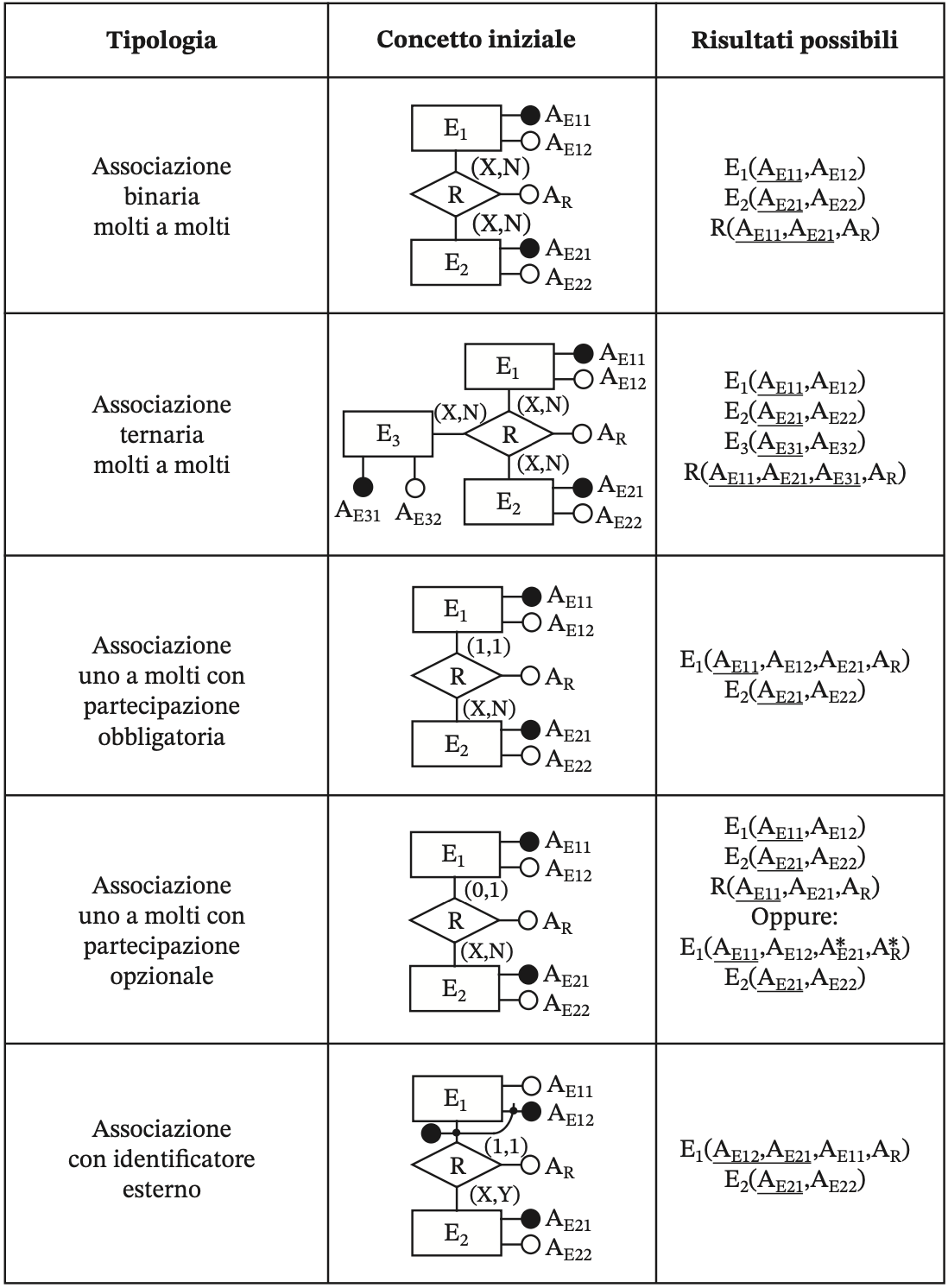
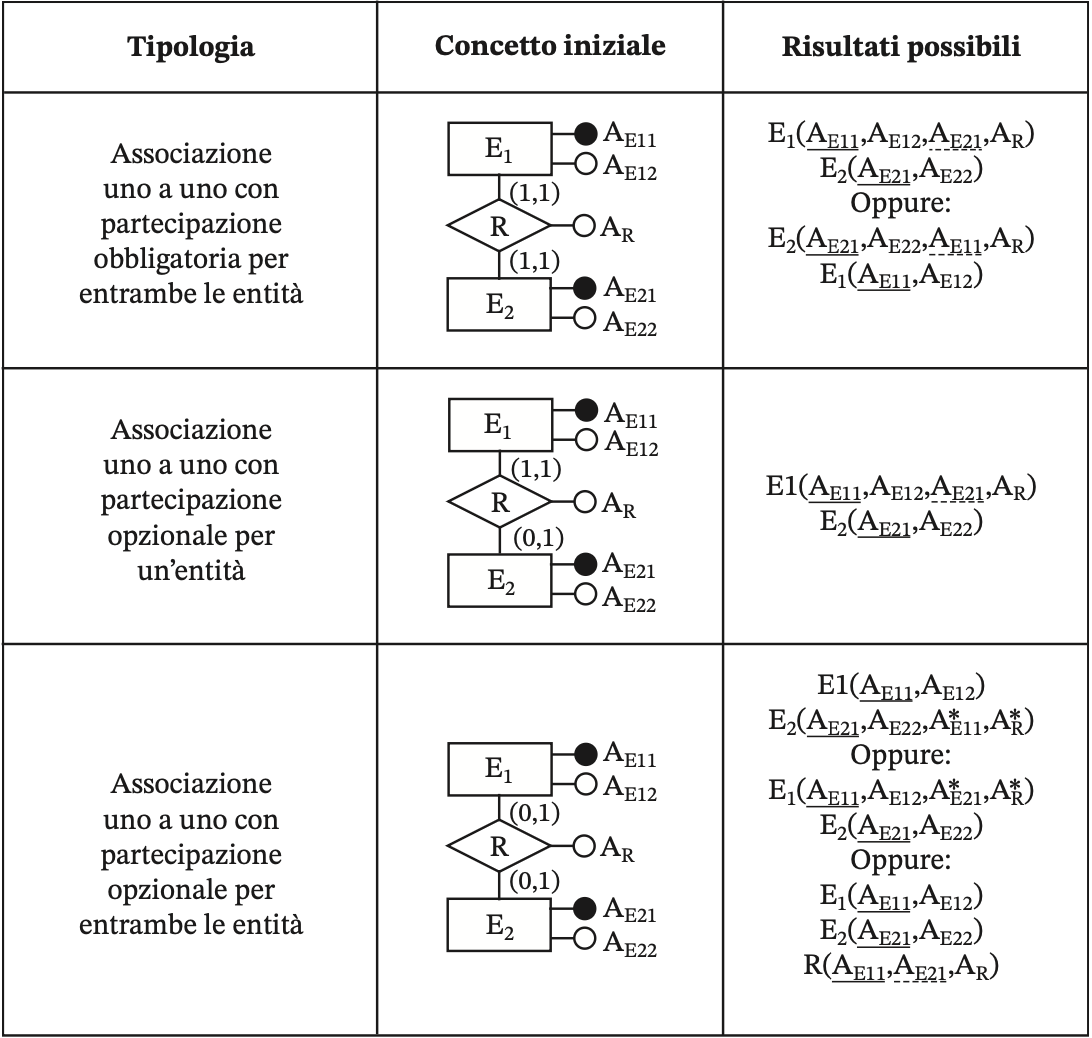
uni
La progettazione logica è la seconda fase del terzo stadio del Waterfall Model, in particolare quella che porta alla realizzazione dello schema logico.
Obiettivo
L’obiettivo di questa fase è quello di tradurre lo schema concettuale prodotto durante la Progettazione Concettuale in uno schema logico che rappresenti gli stessi dati in maniera corretta ed efficiente.
I dati in ingresso sono:
- schema concettuale (Modello Entity-Relationship)
- informazioni sul carico applicativo
- modello logico
Mentre i dati in uscita sono:
- schema logico
- documentazione associata
Il primo passo è la ristrutturazione dello schema E-R (Modello Entity-Relationship), al fine di semplificare la traduzione in schema logico e ottimizzare le prestazioni.
Nota bene, uno schema E-R ristrutturato non è più uno schema concettuale nel senso stretto del termine.
Il secondo passo è la traduzione nel modello logico, a partire dallo schema E-R ristrutturato e dal modello logico.
Valutazione delle prestazioni
Per valutare le prestazioni consideriamo i seguenti indicatori:
- spazio: numero di occorrenze previste
- tempo: numero di occorrenze visitate per portare a termine un’operazione.
Per cominciare si prende l’operazione da eseguire e si costruisce una tavola degli accessi, basata su uno schema di navigazione. - schema di navigazione: per rispondere a questa domanda, quali oggetti devo manipolare e in che ordine?
Attività di ristrutturazione
Analisi delle ridondanze
Una ridondanza è un’informazione significativa ma derivabile, durante questa fase si decide se eliminarle, mantenerle o introdurne di nuove.
Una ridondanza semplifica le interrogazioni ma appesantisce gli aggiornamenti e occupa maggiore spazio.
Le ridondanze possono essere attributi derivabili oppure relationship derivabili.
Eliminazione delle generalizzazioni
Il Modello Logico Relazionale non può rappresentare direttamente le generalizzazioni, si eliminano quindi le gerarchie, sostituendole con entity e relationship.
Le possibilità sono:
- accorpamento delle figlie nel genitore
conviene se gli accessi al padre e alle figlie sono contestuali - accorpamento del genitore nelle figlie
conviene se gli accessi alle figlie sono distinti - sostituzione della generalizzazione con relationship
conviene se gli accessi alle figlie sono separati dagli accessi al padre
sono anche possibili soluzioni ibride, sopratutto in gerarchie a più livelli.
Partizionamento/accorpamento di entity e relationship
Si fa per rendere più efficienti le operazioni, lo scopo è ridurre gli accessi:
- separando attributi di un concetto che vengono acceduti separatamente
- raggruppando attributi di concetti diversi acceduti insieme
Nota bene: ad ogni accesso si legge sempre l’intera informazione.
I casi principali sono: - partizionamento verticale di entità
separare gli attributi in gruppi e separare la entity iniziale nelle due realtà indicate dai gruppi (ad esempio dividere i dati su un impiegato in dati anagrafici e dati lavorativi). - partizionamento orizzontale di relationship
duplicare un attributo di relationship e dividere la relationship in modo che siano entrambe legate alle stesse entity e abbiano quell’attributo uguale. - eliminazione di attributi multivalore
dividere un attributo multivalore in una entity con attributi e legarla alla entity originale tramite relationship. - accorpamento di entity e relationship
il contrario di partizionamento verticale e orizzontale (ho una relationship uno ad uno che lega due entity, accorpiamo tutto in una entity sola).
Scelta degli identificatori primari
Questa è un’operazione indispensabile per la traduzione nel modello relazionale.
La scelta viene eseguita secondo i seguenti criteri:
- assenza di opzionalità
- semplicità
- utilizzo nelle operazioni più frequenti ed importanti
Nel caso in cui nessuno degli identificatori soddisfa questi requisiti si introducono nuovi attributi (codici) appositamente generati.
Traduzione verso il modello Relazionale
L’idea di base per tradurre nel Modello Logico Relazionale è:
- le entity diventano relazioni sugli stessi attributi
- le relationship diventano relazioni sugli identificatori delle entity coinvolte (più gli attributi propri).
Dobbiamo misurare formalmente la qualità di un raggruppamento di attributi in uno schema di relazione.
Per farlo utilizziamo la Normalizzazione e un approccio Top-Down:
- individuiamo alcuni raggruppamenti di attributi con i quali formiamo relazioni che sussistono come tali nel mondo reale
- analizziamo poi queste relazioni e portiamo eventualmente a decomposizioni successive
Gli obiettivi della progettazione logica sono:
- conservazione dell’informazione contenuti nel modello concettuale
- minimizzazione della ridondanza
Da questi obiettivi possiamo derivare alcune linee guida per il progetto:
- Semplice è bello:
- uno schema di relazione deve essere tale che sia semplice spiegarne il significato
- non raggruppare eccessivamente (non complicare)
- evitare ambiguità semantiche
- No alle anomalie:
- lo schema non deve permettere anomalie in inserimento
- l’assenza di anomalie deve essere certificata usando una descrizione formale della semantica: Dipendenza Funzionale.
- se le anomalie possono presentarsi vanno rilevate chiaramente in modo che i programmi che aggiornino il Database operino correttamente.
esempio: Fattura(CodFatt, CodProd, TotDaPagare, CostoNettoProd, IVA)
Semantica attributi:
• CodFatt determina CodProd e TotDaPagare
• CodProd determina CostoNettoProd e IVA
• CostoNettoProd e IVA determinano TotDaPagare
- Meno NULL possibili:
- non inserire in una relazione attributi i cui valori possono essere frequentamente NULL
- se i valori NULL non possono essere evitati, ci si assicuri che siano casi eccezionali
Cheat-sheet