uni
Structured Query Language.
Questo è un linguaggio dichiarativo per interagire con database relazionali, a differenza del C++, che è un linguaggio procedurale.
Dichiarativo vuol dire che dichiari le proprietà del risultato invece di scrivere come lo si ottiene.
Gli statement dell’SQL sono fatte da tre componenti, uno statement anche se va a capo non termina fino a che non si inserisca un punto e virgola.
In un database vi sono più tabelle e possono essere combinate per formare una lista di tabelle. Dividere il database in più tabelle può s volgere diversi motivi, evitare anomalie, evitare ridondanza o distribuire dati.
SQL non è Case Sensitive.
Chiave
La chiave è l’identificatore di un Record, è unica e quindi non può ripetersi e non può essere NULL.
Ci sono poi le chiavi candidate, ovvero attributi in cui non ci sono ripetizioni, ma non sono chiavi a tutti gli effetti.
Query
SELECT Cognome, Nome //proiezione //oppure SELECT * se vuoi tutti gli attributi
FROM Persona //fonte
WHERE Età < 40; //condizioneCondizioni più espressive si ottengono con gli operatori logici:
SELECT CodiceFiscale
FROM Persona
WHERE Età < 40
AND Cognome = 'Lepre';L’ordine in cui si legge, si scrive e viene processata una Query è il seguente:
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- DISTINCT
Direttive
BETWEEN = WHERE Età BETWEEN 45 AND 60; oppure WHERE Età <= 60 AND Età >= 45; include sempre gli estremi.
Le condizioni nel WHERE sono applicate ai record prima di un eventuale raggruppamento.
Valori NULL
Gli attributi non chiave possono essere NULL, ovvero l’informazione manca. Quando nelle condizioni viene esaminato un attributo NULL, a priori assume False, anche NULL=NULL è falso. Se voglio cercare attributi NULL devo usare IS NULL, se voglio attributi non NULL devo usare IS NOT NULL.
NULL ha valore mancante ma può avere un significato logicamente definito (per esempio dataLaurea è NULL = non laureato).
Duplicati
In una tabella non ci sono mai due record(righe) uguali. Due record sono uguali se il valore degli attributi corrispondenti è uguale per tutti gli attributi, i valori degli attributi non chiave invece possono ripetersi.
Se la query restituisce alcuni stessi valori più volte, posso scegliere di eliminarli con DISTINCT. SELECT DISTINCT Cognome ecc, questa parola chiave agisce su tutti gli attributi proiettati.
Usare solo se necessario poiché ha complessità quadratica.
Date
Una data è il tempo trascorso da un reference, che come in tutti i sistemi UNIX è 01/01/1970 (EPOCK). Se la data è negativa è precedente alla Reference.
Formati:
- DATE: YYYY-MM-DD
- TIMESTAMP: YYYY-MM-DD HH:MM:SS
DATE_FORMAT:
| %Y | anno (4 cifre) |
|---|---|
| %y | anno (2 cifre) |
| %M | nome del mese |
| %m | mese (2 cifre) |
| %d | giorno del mese |
| %W | nome del giorno della settimana |
| %w | giorno della settimana {0,…,6} |
| %T | orario (hh:mm:ss) |
Stampare nel seguente formato: (‘dd||mm||yyyy, nome_giorno’): SELECT Matricola, DATE_FORMAT(DataLaurea,'%d %m %Y %W') Indicare la matricola degli studenti che si sono laureati di mercoledì: WHERE DATE_FORMAT(DataLaurea, ‘%w’) = 3;`
Le funzioni DAY,MONTH,YEAR prendono come argomento una data e ne restituiscono, rispettivamente, giorno, mese, anno. YEAR(DataIscrizione) > 2000;
Indicare il cognome degli studenti che si sono laureati 5 anni fa, si usa la parola chiave CURRENT_DATE: WHERE YEAR(DataLaurea) = YEAR(CURRENTE_DATE) - 5;
==Le date in MySQL non possono essere sottratte tramite l’operatore ’-’, ma occorre usare DATEDIFF()== : numero di GIORNI che separano due date: SELECT Matricola, DATEDIFF('2005-07-15'-DataIscrizione) prima viene la date più recente e poi quella più remota.
Non sottrarre o sommare date perché è bestemmia!!!
DATE_ADD e DATE_SUB permettono di sommare o sottrarre intervalli di tempo ad una data e vengono espressi con la keyword INTERVAL.
INTERVAL NumeroInterno [YEAR|MONTH|DAY]
WHERE DataLaurea = DATE_ADD(DataIscrizione, INTERVAL 5 YEAR); oppure
WHERE DataLaurea = DataIscrizione + INTERVAL 5 YEAR;
Altre funzioni:
- DAYNAME()
- MONTHNAME()
- DAYOFWEEK() //1,…,7
- WEEKDAY() //0,…,6
- LAST_DAY() //ultimo giorno del mese della data
- MONTHOFYEAR() //mese in 2 cifre
- WEEKOFYEAR() //numero della settimana dell’anno
- YEARWEEK() //anno e settimana
Operatori
Operatori di aggregazione
Permettono di eseguire calcoli i cui operandi sono i valori assunti da un attributo, in un insieme di record → collassa in un solo record formato da un solo attributo numerico.
Accanto ad una aggregazione posso solo mettere un’altro aggregazione e non altro perchè la tabella scompare.
- conteggio: conta le righe slide che rientrano nella ricerca, conta i risultati.
SELECT count(*) AS VisitePrimoMarzorestituisce il risultato con il nome VisitePrimoMarzo, quindi AS si chiama ridenominazione,COUNT(*)non fa distinzione tra risultati e conta anche i duplicati. Se non voglio contare i duplicati devo usareCOUNT(DISTINCT Attributo) - somma
SELECT SUM(Reddito) AS RedditoTotale - minimo/massimo
SELECT MAX(Reddito) FROM paziente; - media
SELECT AVG(Reddito) AS RedditoTotale - Deviazione Standard
SELECT STDDEV(Reddito) AS DeviazioneStandard
Query su più Tabelle
Per riunire le tabelle si utilizza JOIN.
natural join:
Combina una riga della prima tabella con una riga della seconda tabella se l’attributo omonimo(che ha lo stesso nome) ha lo stesso valore in entrambe.
SELECT DISTINCT M.Nome, M.Cognome
FROM Visita V
NATURAL JOIN
Medico M;
//dove V ed M sono Alias per le tabelle.inner join
Crea tante righe quante ne ha la tabella con la quale vengono esplosi i campi.?
SELECT DISTINCT M.Nome, M.Cognome
FROM Visita V
INNER JOIN
Medico M ON V.Medico = M.Matricola;
//dove V ed M sono Alias per le tabelle.left/right outer join
Date due tabelle, combinano ogni record della prima con tutti i record della seconda che soddisfano una condizione, mantenendo tutti i record di una delle due tabelle, riempendo gli attributi mancanti con NULL (sinistra→mantiene sinistra, destra →mantiene destra).SELECT V.* FROM Visitva V LEFT OUTER JOIN Medico M ON V.Medico = M.Matricola WHERE Cognome IS NULLself join(INNER JOIN)
Combina le righe di una tabella cone le riga di se stessa se si verifica la condizione
indicare il codice fiscale dei pazienti che sono stati visitati più di una volta da un ostesso medico della clinica nel mese corrente
SELECT DISTINCT V1.Paziente
FROM Visita V1
INNER JOIN
Visita V2 ON (
V.2Medico = V1.Medico
NAD V2.Paziente = V1.Paziente
AND V2.DATA <> V1.Data
)
WHERE MONTH(V1.Data)=MONTH(CURRENT_DATE)
AND YEAR(V1.Data) = YEAR(CURRENT_DATE)
AND MONTH(V2.Data) = MONTH(CURRENT_DATE)
AND YEAR(V2.Data) = YEAR(CURRENT_DATE);
//se non metto DISTINCT il paziente compare n-1 volte.cross join
prodotto cartesiano: moltiplica ogni tupla della prima tabella con tutte le tuple della seconda tabella
SELECT COUNT(DISTINCT P.CodFiscale)
FROM Paziente P
CROSS JOIN
Medico M
WHERE P.Nome = M.Nome;Se ci sono attributi su più tabelle che hanno lo stesso nome si verifica ambiguità e si rende necessario differenziarli con la ridenominazione, molto apprezzato l’uso dell’UpperCamelCase.
Il join si può fare, con attenzione, su un numero di tabelle maggiore di due.
L'ordine non importa, tanto il DBS riscrive la query come meglio desidera.
Ridenominazione
È possibile ridenominare una colonna del result set tramite l’operatore AS , mentre per combinare più colonne è possibile utilizzare l’operatore +
SELECT nomevecchio AS nomenuovo
SELECT Citta + ', ' + via + ', ' + cap AS indirizzoRaggruppamento/Group by
Suddivide un insieme di record in gruppi di record e in ogni ogni gruppo il valore di un (o più) attributo è costante in tutti i record.
Deve essere usato insieme ad Operatori di aggregazione.
OGNI GRUPPO GENERA UN SOLO RECORD NEL RESULT SET.
La cardinalità minima per ogni gruppo è 1, altrimenti il record per quel gruppo non si genera.
Indicare la parcella media dei medici di ciascuna specializzazione
select specializzazione, avg(parcella) as parcellamedia
from medico
group by specializzazione;
l´operatore avg() è applicato gruppo per gruppo (calcola un valore riepilogativo per il gruppo)
specializzazione invece assume lo stesso valore in un gruppoHaving
Si usa insieme a GROUP BY per porre condizioni sui gruppi, ad esempio raggruppa per specializzazione ma mostra solo le specializzazioni con più di due medici.
Queste condizioni sono applicate ai gruppi dopo il raggruppamento.
REGOLA: nelle interrogazioni con raggruppamento, le condizioni esprimibili con operatori di aggregazione devono sempre essere argomento della clausola having.
SELECT Specializzazione
FROM Medico
GROUP BY Specializzazione
HAVING COUNT(*) > 2;Derived Table
Sono tabelle volatili (vengono cancellate alla fine dell’esecuzione) che possono essere incapsulate nel FROM, sono utili per costruire risultati intermedi. Per costruire una derived table è sufficiente eseguire una ridenominazione con AS di una query, esempio:
Indicare la matricola dei medici che non hanno mai visitato di giovedì
SELECT DISTINCT V1.Medico
FROM Visita V1 LEFT OUTER JOIN
(
SELECT V2.Medico |
FROM Visita V2 |-> derived table
WHERE DAYOFWEEK(V2.Data) = 4 |
)
AS D |-> alias (obbligatorio) della Derived Table
ON V1.Medico = D.Medico |oppure| USING(Medico)
WHERE D.Medico IS NULL;Riordinamento Valori
Per ordinare i risultati in base ai valori in una colonna posso usare ORDER BY.
SELECT name, grade
FROM students
ORDER BY grade DESC, name ASC;Prima ordina su grade, se ci sono pareggi allora li ordina su name.
Common Table Expression (CTE)
Sono result set dotati di identificatore che possono essere usati prima di una query per costruire risultati intermedi.
Sono parti di codice i cui risultati sono stoccati in memoria, nominati, e usati dalla query immediatamente dopo.
WITH
name1 AS (SELECT ecc FROM ecc WHERE ecc)
,
name2 AS (query2)
,
...
,
nameN AS (queryN)
(query finale);Subquery
Sono Query che posso essere incapsulate (in modo correlato non correlato) in un’altra query.
Queste rappresentano una alternativa al join per query su più tabelle.
Sono formate da una query esterna ed una query interna.
I record ottenuti dalla subquery non dipendono dalla outer query.
Noncorrelated subquery
Si incapsulano nel WHERE per ottenere risultati (eliminati alla fine dell’esecuzione) usati dalla outer query per determinare il result set finale. Si usa tramite IN o NON IN, per controllare se il record della outer query è o non è nel result set della subquery.
IS: un record fa parte del risultato se i valori che assume su un sottoinsieme di attributi si trova anche in (almeno) un record del result set della subquery
Indicare nome, cognome e parcella degli ortopedici |SPEZZARE| che hanno effettuato almeno una visita nell anno 2013
select medico.nome, medico.cognome, medico.parcella |
from medico |-> outer query
where medico.specializzazione = 'ortopedia' |
and medico.matricola IN (
select visita.medico |
from visita |-> subquery
where year(visita.data) = 2013 |
);Teorema di equivalenza join-subquery
Data una query con subquery è sempre possibile passare alla versione basata su join, e viceversa.
Subquery scalare
Questa restituisce un unico record, composto da un unico attributo.
Indicare il numero degli otorini aventi parcella più alta della media delle parcelle dei medici della loro specializzazione.
SELECT COUNT(*)
FROM Medico M1
WHERE M1.Specializzazione = ‘Otorinolaringoiatria’
AND M1.Parcella > (
SELECT AVG(M2.Parcella)
FROM Medico M2
WHERE M2.Specializzazione = ‘Otorinolaringoiatria’
);Correlated Subquery
Il risultato (uno per ogni tupla della query esterna) dipende da ciascuna tupla della query esterna, simile alla chiamata di una funzione.
Una correlated subquery è eseguita per ogni record della query esterna e il suo risultato ne dipende.
Questa può anche essere inserita nel SELECT, basta che sia una subquery scalare (!).
Per essere una correlated subquery basta che la subquery faccia riferimento al suo interno ad un valore della query esterna.
SELECT DISTINCT V1.Medico
FROM Visita V1
WHERE YEAR(V1.Data) = 2013
AND MONTH(V1.Data) = 10
AND V1.Paziente NOT IN (
SELECT V2.Paziente
FROM Visita V2
WHERE V2.Medico = V1.Medico
AND V2.Data < V1.Data
)Subquery nel SELECT:
Considerato ciascun paziente di sesso maschile, indicarne il nome e
il numero di visite effettuate
SELECT P.CodiceFiscale, (SELECT COUNT(*)
FROM Visita V
WHERE V.Paziente = P.CodFiscale) AS TotaleVisite
FROM Paziente P
WHERE P.Sesso = ‘M’Costrutto EXISTS
Questo è un modo per scrivere subquery correlate. Controlla solo se il resultset della subquery esiste o meno (controlla quindi se ha almeno 1 record e non esiste se è vuoto).
Una visita di controllo è una visita in cui un medico visita un paziente già visitato precedentemente almeno una volta. Indicare medico, paziente e data delle visite di controllo del mese di Gennaio 2016
SELECT V1.Medico, V1.Paziente, V1.Data
FROM Visita V1
WHERE MONTH(V1.Data) = 1
AND YEAR(V1.Data) = 2016
AND EXISTS
(
SELECT *
FROM Visita V2
WHERE V2.Medico = V1.Medico
AND V2.Paziente = V1.Paziente
AND V2.Data < V1.Data
);Divisione
La divisione tra una relazione A ed una relazione B produce una relazione C che contiene tutte le tuple di A che hanno una relazione con OGNUNA delle tuple di B.
In SQL abbiamo 2 modi per implementare la divisione:
- indicare i pazienti visitati da TUTTI i medici:
SELECT P.CodFiscale
FROM Paziente P
WHERE NOT EXISTS (
SELECT *
FROM Medico M
WHERE NOT EXISTS (
SELECT *
FROM Visita V
WHERE V.Medico = M.Matricola AND V.Paziente = P.CodFiscale
)
);
SELECT V.Paziente
FROM Visita V
GROUP BY V.Paziente
HAVING COUNT(DISTINCT V.Medico) = (SELECT COUNT(*))Stored Procedure
Le stored procedures sono programmi dichiarativo-procedurali memorizzati nel DBMS, vengono invocati tramite chiamata e possono ricevere e/o restituire valori.
Le applicazioni possono essere autorizzate ad eseguire stored procedures, ma gli è vietato l’accesso alle tabelle.
Le restrizioni sono impostate con opportuni grant.
Sono supportate a partire dalla versione 5.0 di MySQL.
Scrivere una stored procedure che restituisca le specializzazioni mediche offerte dalla clinica:
DROP PROCEDURE IF EXISTS mostra_specializzazioni;
DELIMITER
$$
CREATE PROCEDURE mostra_specializzazioni( )
BEGIN
SELECT DISTINCT Specializzazione
FROM Medico;
END
$$
DELIMITER ;
per chiamarla poi:
CALL mostra_specializzazioni();Variabili Locali
Queste sono usate all’interno di una stored procedure per memorizzare informazioni intermedie di ausilio, devono essere dichiarate tutte insieme all’inizio del body, subito dopo CREATE PROCEDURE.
DECLARE nome_variabile tipo(size) DEFAULT valore_default;Il valore default se non specificato è NULL. La capacità se non specificata è quella di default del tipo.
è possibile assegnare un valore ad una variabile in due modi: SET oppure SELECT+INTO:
DECLARE min_visite_mensili INT DEFAULT 0;
.
.
SET min_visite_mensili =
(
SELECT ecc
FROM ecc
)
oppure
DECLARE visite_mese_attuale INT DEFAULT 0;
.
.
SELECT COUNT(*) INTO visite_mese_attuale
FROM ecc;Variabili User-Defined
Queste sono inizializzate dall'utente senza necessità di dichiarazione (ovvero faccio direttamente SET) e il loro ciclo di vita equivale alla durata della connessione al server MySQL.
Queste variabili non necessitano di un tipo definito, possono assumere qualsiasi tipo di dato.
Il loro contenuto è visibile ovunque, ma solo all’utente che le ha inizializzate.
Il loro identificatore deve iniziare con @ e sono case insensitive.
Variabili user-defined e locali possono solo assumere valori scalari.
Parametri di una stored procedure
In ingresso
I parametri sono in ingresso per default se non specificato.
Non posso passare riferimento come parametro, sono infatti passati per copia e quindi possono essere letti ma non modificati.
Scrivere una stored procedure che stampi la parcella media di una specializzazione specificata come parametro
DROP PROCEDURE IF EXISTS parcella_media_spec;
DELIMITER
$$
CREATE PROCEDURE parcella_media_spec(IN _specializzazione VARCHAR(100))
BEGIN
SELECT AVG(medico.parcella)
FROM medico
WHERE medico.specializzazione = _specializzazione;
END
$$
DELIMITER;
CALL parcella_media_spec('ortopedia'); |-> chiamataIn uscita
Un parametro in uscita può essere modificato per assumere il valore del risultato della stored procedure.
Scrivere una stored procedure che restituisca il numero di pazienti visitati da medici di una data specializzazione, ricevuta come parametro
DROP PROCEDURE IF EXISTS tot_pazienti_visitati_spec;
DELIMITER
$$
CREATE PROCEDURE tot_pazienti_visitati_spec(
IN _specializzazione VARCHAR(100),
OUT totale_pazienti_ INT)
BEGIN
SELECT COUNT(DISTINCT visita.paziente) INTO totale_pazienti_
FROM visita
inner join medico
on visita.medico = medico.matricola
where medico.specializzazione = _specializzazione;
END
$$
DELIMITER;
CALL tot_pazienti_visitati_spec('neurologia', @quantipazienti);
SELECT @quantipazienti;Istruzioni condizionali
Permettono di modificare il flusso di esecuzione.
IF condizione THEN
blocco di istruzioni
ELSEIF condizione THEN
blocco di istruzioni
ELSE
blocco di istruzioni
END IF; |->obbligatorio punto e virgolaEsercizio Riepilogativo Stored Procedures, variabili locali, IF
Scrivere una stored procedure che riceva come parametro un intero t e una
specializzazione s e restituisca in uscita true se il numero di visite della specializzazione s nel mese in corso è superiore a t, false se è inferiore, e NULL se è uguale.
DROP PROCEDURE IF EXISTS esercizio;
DELIMITER
$$
CREATE PROCEDURE esercizio(IN _t int, IN _s char(100), OUT passed bool)
DECLARE visite_mese_attuale INT DEFAULT 0;
SET visite_mese_attuale =
(
SELECT COUNT(*)
FROM visite v INNER JOIN medico m
ON v.medico = m.matricola
WHERE m.specializzazione = s AND
MONTH(v.data)=MONTH(CURRENT_DATE) AND
YEAR(v.data)=YEAR(CURRENT_DATE)
);
IF nvisite > t THEN SET passed = true;
ELSEIF nvisiste < t THEN SET passed = false;
ELSE SET passed = NULL;
END
$$
DELIMITER;Istruzioni CASE
Equivale allo switch del C++.
CASE
WHEN condizione THEN
istruzioni
WHEN condizione THEN
istruzioni
END CASE; Istruzioni Iterative
While
WHILE condizione DO
istruzioni
END WHILE;Repeat
REPEAT
istruzioni
UNTIL condizioneUscita
END REPEAT
# la condizione è controllata DOPO ogni iterazioneLoop
loop_label: LOOP
istruzioni+controllo condizione
END LOOP;
# le condizioni di uscita sono gestite dal programmatore all'interno del blocco di istruzioni, tramite un salto alla label loopIstruzioni di Salto
LEAVE: devi specificare quale loop vuoi abbandonareITERATE: devi specificare a quale label saltare
Vengono usate insieme a blocchiIFoCASE.
Cursori
Scorrono i record di un result set, solo in avanti, per effettuare delle azioni all’interno di istruzioni iterative (come un puntatore).
Vanno dichiarati solo immediatamente dopo la dichiarazione di tutte le variabili.
Per usare un cursore va aperto, poi si effettua il prelievo, poi va chiuso (open-fetch-close).
DECLARE nomeCursore CURSOR FOR
querySQL;
OPEN nomeCursore;
FETCH nomeCursore INTO listaVariabili
CLOSE nomeCursore;Handler
Sono gestori di situazioni, utili quando si usano i cursori, per riconoscere la fine del result set.
Possono essere definiti subito dopo le definizioni delle variabili e dei cursori.
Not found handler
Esprime l’evento “oggetto (record) non trovato”.
Viene utilizzato per gestire il fine corsa nella scansione di un result set effettuata all’interno di ciclo dove si scorre un cursore.
DECLARE finito INTEGER DEFAULT 0;
DECLARE cursore CURSOR FOR
queryCheRestituisceIlResultSetR;
DECLARE CONTINUE HANDLER FOR NOT FOUND
SET finito = 1;
# ciclo di fetch dove si scorre il result set, quando si finisce la tabella viene settata la variabile a 1Manipolazione Dati
Inserimento Dati
Se una informazione non viene inserita, viene automaticamente impostato il valore default (impostato all’atto della creazione della tabella).
INSERT INTO nomeTabella[(nomeAttributo1,nomeAttributo2,ecc)]
VALUES('valore','valore',ecc,numeriSenzaVirgolette);
# Non importa specificare la tabella in cui inserire se inserisco tutti i campi rispettandone l'ordine
# Non importa specificare i nomi degli attributi se sono tutti
oppure
INSERT INTO Tabella
queryPerRicavareDati;Aggiornamento Dati
Non si può inserire la tabella target nella condizione WHERE.
UPDATE nomeTabella
SET attributo1 = valore1, att..
WHERE condizioneCancellamento Dati
Non si può inserire la tabella target nella condizione WHERE.
DELETE FROM nomeTabella
WHERE condizioneesempio
DELETE FROM Medico
WHERE Matricola IN (
SELECT * FROM (
querySelezione
) AS D);Window Functions (a.k.a. analytic functions)
Queste funzioni affiancano ad ogni record un valore ottenuto da un’operazione eseguita su un insieme di record logicamente connessi al record.
OVER
La clausola OVER applica una funzione di tipo aggregate o non-aggregate a un partition (insieme di record) associato ad un record di un result set.
Se OVER non ha argomento, la partition è la stessa per ogni record e coincide con il result set della query, senza la funzione su cui è applicata OVER.
Scrivere una query che indichi per ogni cardiologo, la matricola, la parcella e la parcella media della sua specializzazione.
SELECT m.matricola, m.parcella, AVG(m.parcella) OVER()
FROM medico m
WHERE m.specializzazione = 'Cardiologia';PARTITION BY
Serve per applicare una funzione aggregate o non-aggregate tramite OVER a singole partizioni del result set.
Scrivere una query che indichi per ogni medico, la matricola, la specializzazione, la parcella e la parcella media della sua specializzazione.
SELECT m.matricola, m.specializzazione, m.parcella,
AVG(m.parcella) OVER(
PARTITION BY
m.specializzazione
)
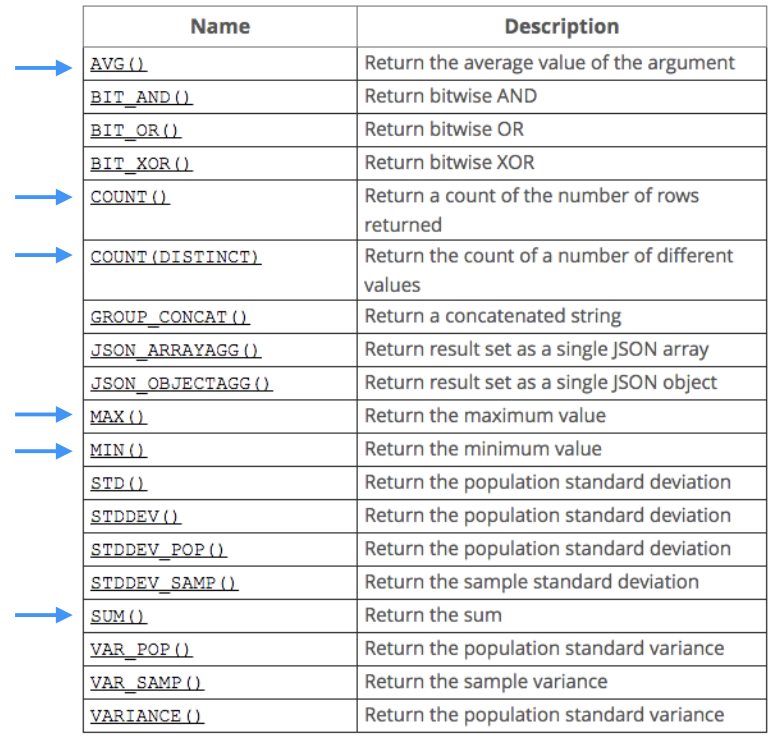
FROM medico m;Aggregate Functions
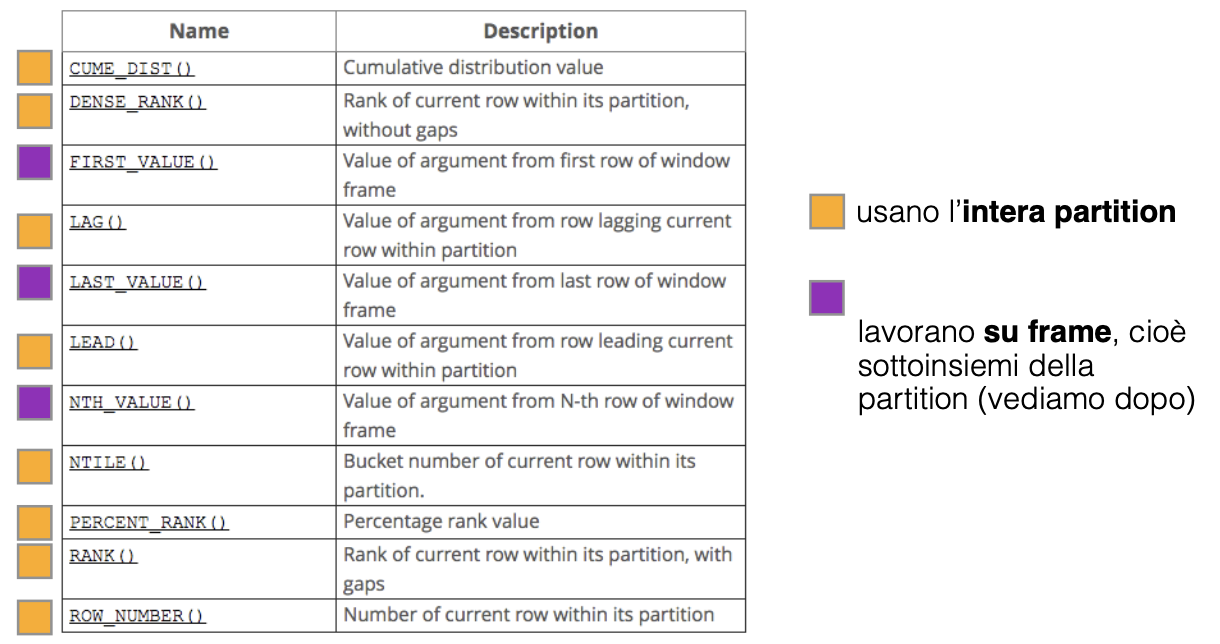
Non-Aggregate Functions
Funzioni Frequenti
- COUNT()
- MAX()
- MIN()
- AVG()
- SUM()
- ROW_NUMBER(): assegna un numero ad ogni riga
- RANK(): assegna un numero ad ogni riga, con buchi in caso di pari merito
- DENSE_RANK(): assegna un numero ad ogni riga, senza buchi in caso di pari merito
- LAG(): permette di affiancare a ogni record il valore di un record posizionato posizioni prima del record all’interno della partition associata ad .
- LEAD(): stessa cosa ma con record successivi a quello attuale
Esempio:
Effettuare una classifica della convenienza dei medici dipendentemente dalla
loro parcella. Restituire matricola, cognome, specializzazione, parcella e posizione in classifica.
SELECT ecc, RANK() OVER (
ORDER BY m.parcella # DESC se voglio decrescente
)
FROM medico m;Sintassi alternativa con WINDOW
SELECT ecc, RANK() OVER w AS rankGlobale
FROM ecc
WHERE ecc
WINDOW w AS (PARTITION BY .. ORDER BY .. DESC);